
背景介紹
本文的筆者是陳志傑,2015至2020年有幸參與了Google生產環境零信任(Zero Trust in Production Environments)的理論與實踐。在此背景下開發的Binary Authorization for Borg (BAB) 系統已經在谷歌生產環境中實現了全面覆蓋:任何人在生產環境中以任何服務的身份運行任何軟體包之前,都必須為目標服務建立一個足夠強的BAB安全策略。不符合BAB安全策略的程式將不會被允許以對應服務的身分運作。

在實現和推廣這種生產環境零信任的過程中,BAB團隊走了不少彎路,但也獲得了許多經驗。從2017年開始,BAB團隊開始把這些實務經驗上升到理論,並陸續發布了一系列的白皮書( BeyondProd, Binary Authorization for Borg, SLSA: Supply-chain Levels for Software Artifacts), 書籍( Building Secure and Reliable Systems) 以及報告( Evolve to zero trust security model with Anthos security, Zero Touch Prod)。同時也開始將這種零信任理念推廣到更多應用場景,包括公有雲上的零信任,公有雲自身基礎設施的零信任,安卓和Chrome自身及其App的開發零信任。
本次分享的內容全部基於以上谷歌已經公開的資料,並未洩漏谷歌公司機密或違反任何保密協議。本文的結論僅代表作者個人觀點,不一定是谷歌官方的觀點。
什麼是零信任
什麼是零信任?不同的人很有可能會給出不同的答案。有人說零信任就是工作負載微隔離(Workload micro-segmentation);有人說零信任就是持續威脅監測(Continous threat monitoring);有人說零信任就是用對端的信任取代對網路的信任(Trust endpoints, not the network);有人說零信任就是雙向TLS認證(mTLS)。這些都有道理,但也顯然不全面。
在這裡,筆者想藉用一個關於機器學習的戲謔之辭:「機器學習就是美化了的統計學(Machine learning is glorified statistics)。」類似的,零信任就是美化了的最小權限(Zero trust is glorified least privilege)。這明顯也不準確,因為機器學習和零信任都要比統計學和最小權限更強調具體的問題和應用場景。機器學習和零信任都不是單一學科和單一理論,而是為了解決實際問題發展起來的在多個領域(比如數學,計算機架構,分佈式系統,存儲,網絡等)的創新實踐。
由此可見,我們對於零信任,不必太過拘泥於定義和理論,而是要把它跟實踐結合,從具體的要解決的問題和應用場景出發。所以我們暫時結合本文裡的問題和應用場景,將零信任定義為:從要保護的資料和權限出發,對生產環境中的信任的全面削減和重塑(Reduction and reconsruction of trust in production with regard to protected data and privileges)。
比定義零信任更重要的問題是:為什麼要做零信任?
為什麼要做零信任
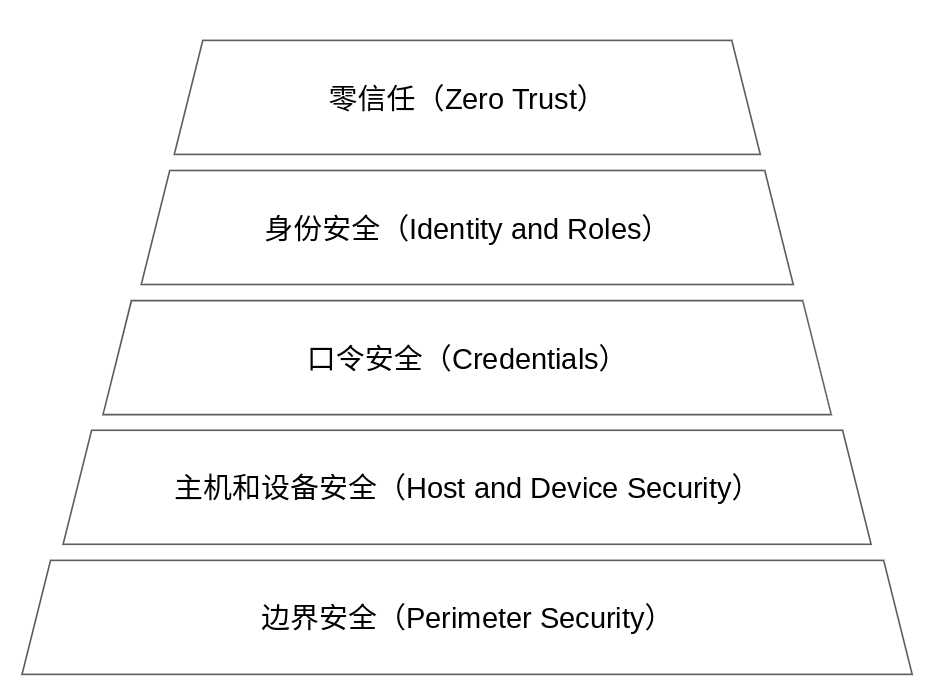
為什麼要做零信任?最本質的,是因為我們有一些重要的資料或權限需要保護,而現有安全體系在雲端原生時代已無法提供足夠的保護。使用者個人隱私數據,員工薪資數據,修改密碼的權限,關閉關鍵系統的權限等等都是被保護的物件。這些資料和權限最初是由基於邊界安全(Perimeter Security)的網路存取控制來保護的,例如公司內網和VPN,當一台設備連入公司內網後,就繼承了獲取這些資料和權限的權利。後來,人們又開始引入基於IP的或基於使用者名稱密碼的存取控制,以及更細緻的基於身分和角色(Identity and Role)的存取控制。但是這些已經無法滿足在雲端原生環境下,尤其是像Google這樣具有複雜的企業IT系統的資料和權限保護的要求。
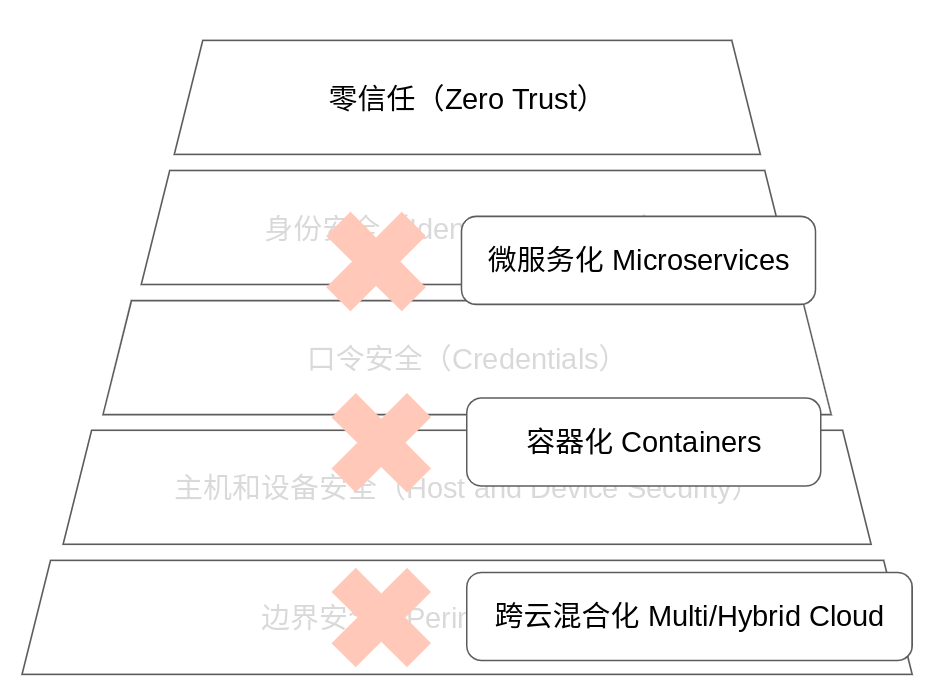
雲原生帶來了以下挑戰:一是企業IT系統已經從單機房模式進化到了跨雲混合(multi and hybrid cloud)的模式,這導致了邊界的模糊和基於邊界保護的安全的低效;二是基於容器(Containers)的計算導致了宿主機的不確定性,同一個服務可能在不斷線的情況下隨時從一台實體主機遷移到另一台實體主機,這導致了基於主機的安全防護已經無法進一步實現基於服務邏輯的深層防護;三是微服務(Microservice)和細粒度的API增加了攻擊面,身份和角色已經不單單是終端用戶的身份和角色,而是微服務之間交互時的更細粒度的身份和存取控制。
從谷歌當時的處境出發,2015年左右時,我們在內部已經實現了比較成熟的基於密鑰和身份認證的權限管理系統,但有兩個安全威脅引起了我們的注意:一是後斯諾登時代,資料中心的機器之間通信,如何建立互信,如何保證一台被入侵的主機或一個被入侵的服務不會影響生產環境中的其他部分?二是當我們對單發(One off)的資料和權限存取有了很好的授權和審計系統之後,如何應對像機器學習這樣批量(Batch)的資料和權限存取帶來的大規模資料外洩的隱患?建立一個基於零信任的內生風險(Insider Risk)管控系統迫在眉睫。
當然,這一切都基於一個紮實傳統安全基本面:網路和主機防護系統,可信任啟動,金鑰管理系統,身分認證和管理系統等等。零信任是基於這個安全基本面的上層建築。
零信任的三要素:信任鏈,身分2.0與持續存取控制
信任鏈,身分2.0和持續存取控制是零信任的三大要素。
信任鏈
零信任並不是完全沒有信任,而是明確的從幾個基本的最小化的信任根(Root of Trust)開始,重構信任鏈(Chain of Trust)的過程。幾個典型的例子包括:多因子認證(MFA,Multi-Factor Authentication)是人類的身份的信任根;可信任平台模組(TPM,Trusted Platform Module)和可信任啟動(Trusted Boot)是機器的身份的信任根;而原始碼和可信任建置(Trusted Build)是軟體的信任根。對於一個龐大的IT系統的信任就是從這些最基本的信任根開始,透過一系列的標準化流程(Standard Process)建立的一個完整的信任鏈(也有人稱其為信任樹Tree of Trust 或信任網Web of Trust)。
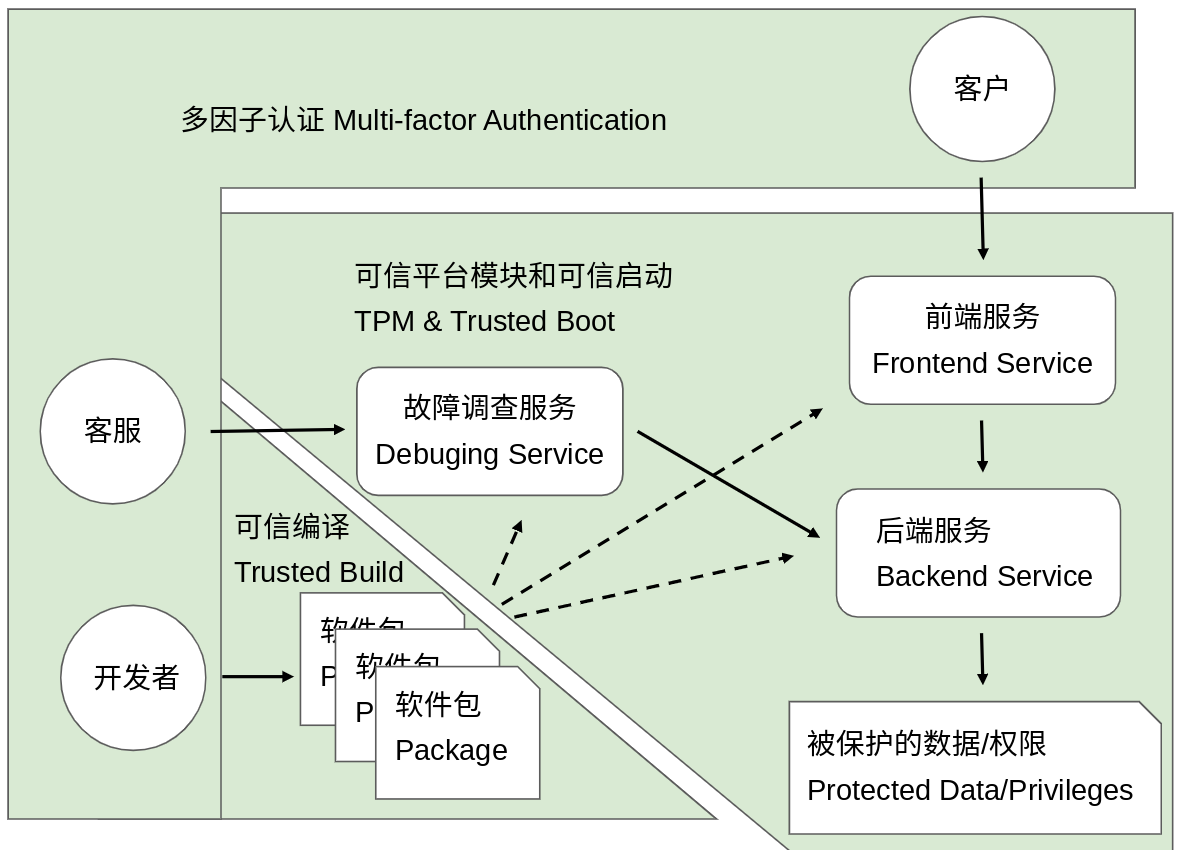
身份2.0
身份2.0是對於以上的信任鏈的標準化,以便於在安全存取策略中使用這些在建立信任過程中收集到的資訊。在身份2.0中,一切本體(Entity)都有身份,用戶有用戶身份,員工有員工身份,機器有機器身份,軟體也有軟體身份;在身份2.0中,一切訪問(Access)都帶有多重身份(又稱為存取背景Access Context),例如對於資料庫中一行資料的存取就會帶有類似「為了幫助使用者解決一個技術問題,員工A在使用者B的授權下透過軟體C在機器D上請求存取」 這樣的訪問背景。
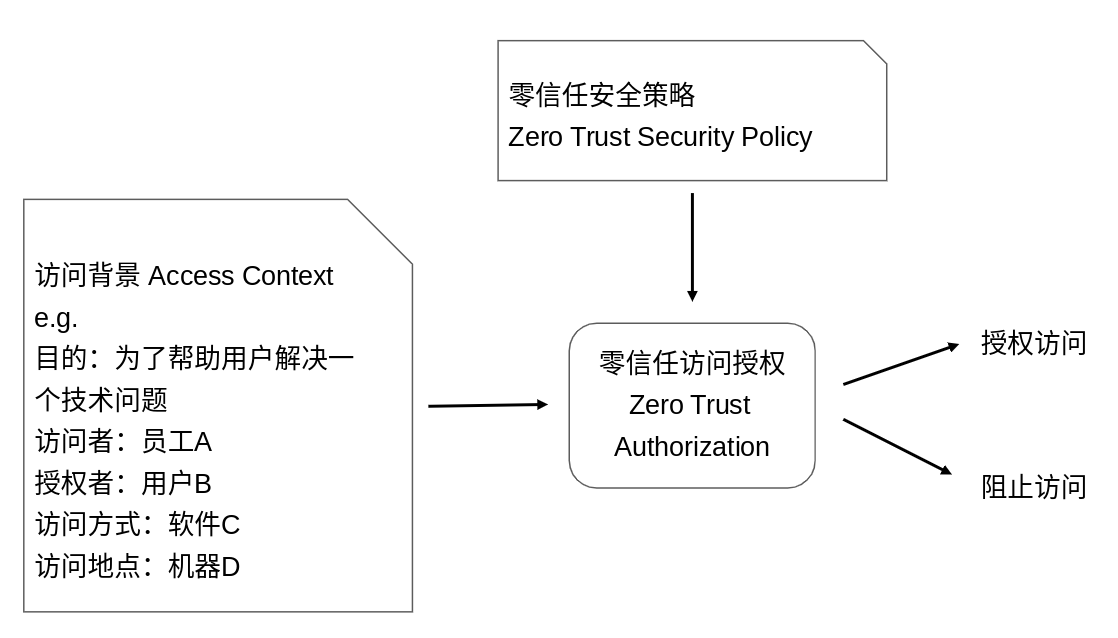
持續存取控制
有了身分2.0提供的豐富的身分和存取背景信息,我們就可以基於此建立一套持續存取控制體系(Continous Access Control)。持續存取控制會在軟體開發和運作的各個環節持續地進行存取控制。幾個典型的例子包括:在員工登入時要求提供多因子認證;在部署軟體時要求軟體是從信任的源碼庫在安全的環境中構建而來,並經過代碼評估(Code Review);在主機之間建立連線時要求雙方提供主機完整性證明;在微服務取得特定使用者資料時要求提供該使用者的授權令牌(Authorization Token)。
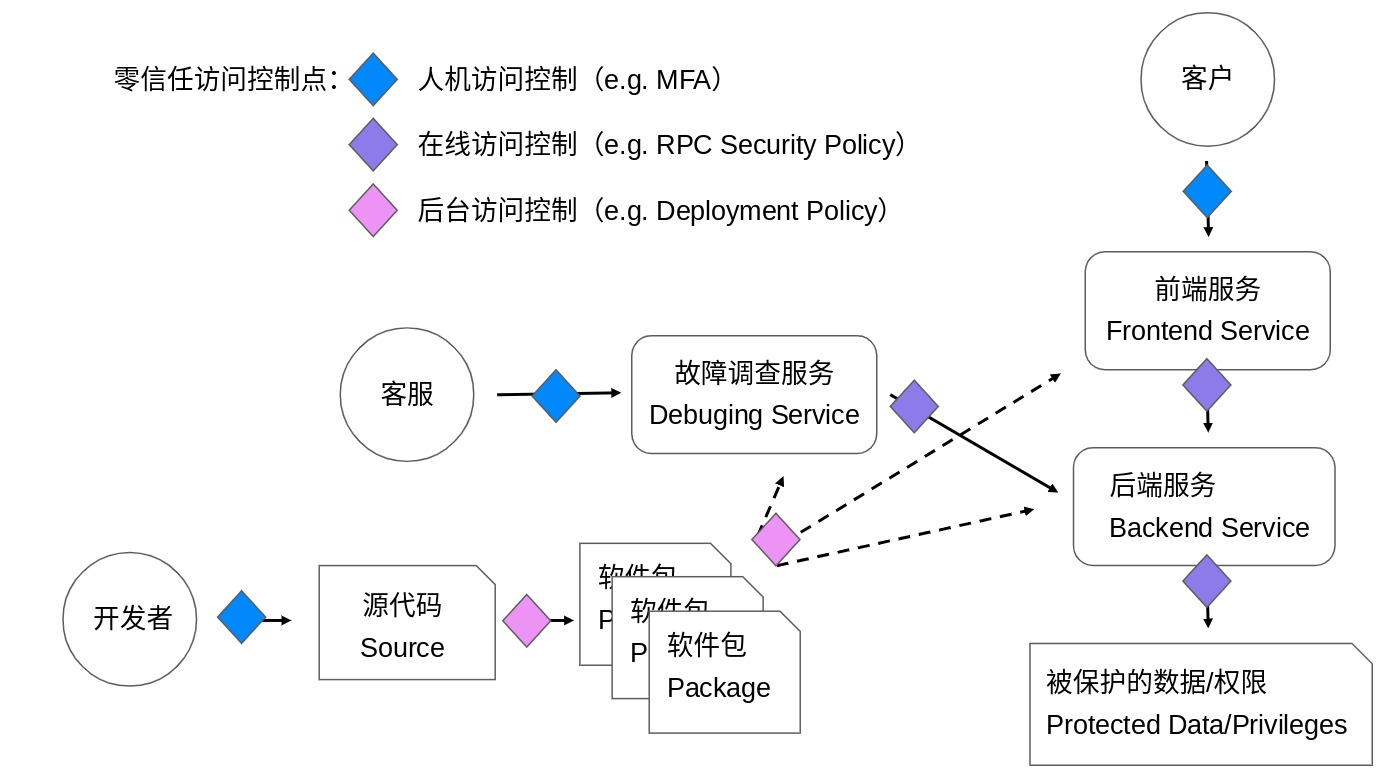
零信任部署實例
在本節中,我們提供兩個具體的零信任部署實例:第一個是使用者如何取得自己的數據,第二個是開發者如何透過修改原始程式碼來改變生產環境中的資料存取行為。谷歌對這兩個案例的資料存取控制都遵循零信任的原則。
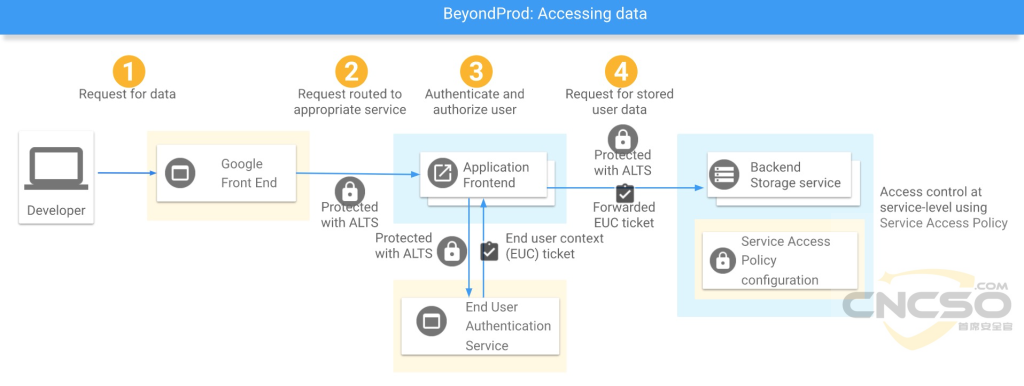
使用者存取自己的數據
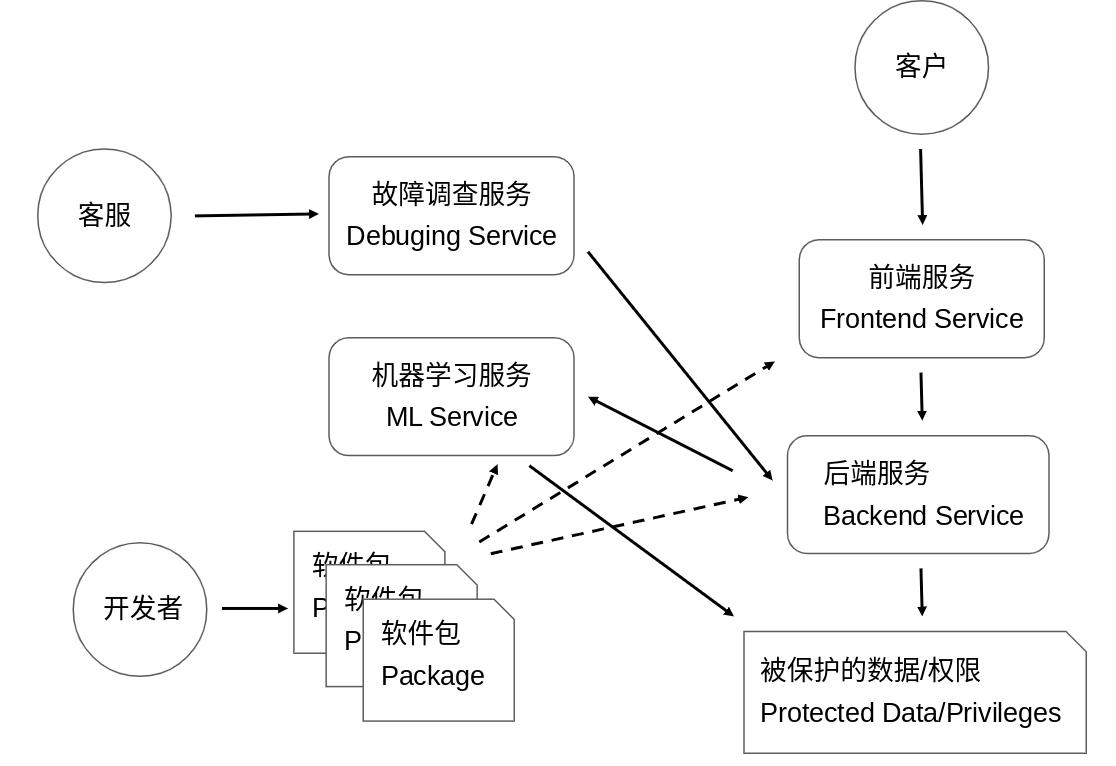
當使用者透過Google的服務存取自己的資料時,請求會透過使用者和Google Front End(GFE)之間的加密連線(TLS)先到達GFE。 GFE轉用更有效率和安全的協定和資料結構將使用者請求分發到各個後端服務共同完成使用者請求。例如TLS會被換為Application Layer TLS(ATLS)。面向使用者的口令會被轉換為更安全的End User Context Ticket(EUC)。這些置換旨在根據實際請求降低內部連接和令牌的權限,使得特定的ATLS和EUC只能存取局限於此請求的資料和權限。
以下為BeyondProd原圖,圖中Developer實際上應該是User:
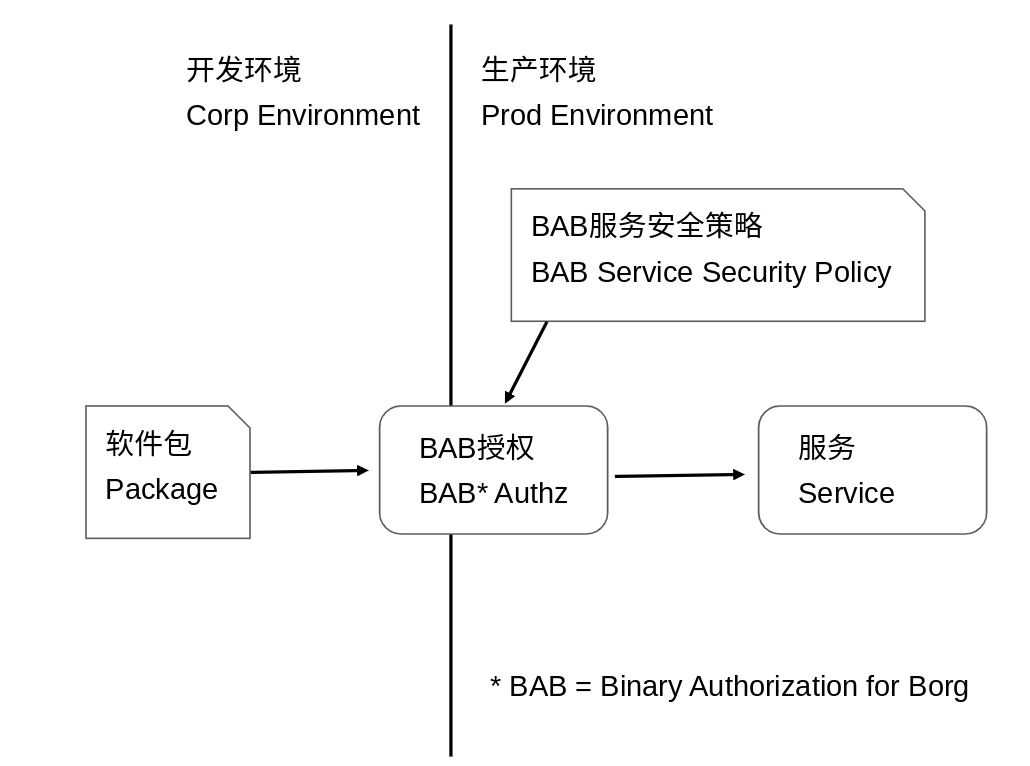
開發者改變軟體資料存取行為
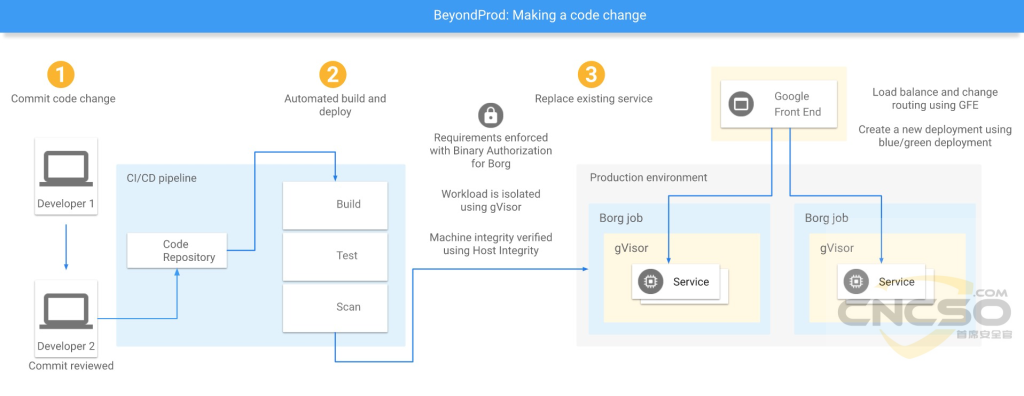
當開發者希望透過改變服務的程式碼來改變一個服務的資料和權限存取行為時(開發者無法取得生產主機的任意指令運行權限,如SSH),該程式碼修改會經過一系列的流程來將對開發者及其團隊的信任轉化為對新的服務的信任:流程中所有涉及的人員均通過多因子認證來確立身份,代碼修改會被一個或以上有審批權限的人評估,只有獲得足夠多的授權的程式碼才會被合併入中央程式碼庫,中央程式碼庫的程式碼會被一個同樣受BAB保護的可信構建服務集中構建,測試和簽名,構建後的軟體會在部署環節通過目標服務的BAB策略認證(例如GMail的服務只能運行程式碼庫特定位置的經過充分程式碼評估和測試的程式碼),軟體運行時也會根據對應的BAB安全策略進行運行時隔離:不同BAB服務策略管轄的服務會被運行在不同的隔離區。
以下為BeyondProd原圖,詳情請參閱原文:
實務經驗和教訓
以人為本,從流程建立信任
在以BeyondCorp實現開發環境(Corp Environment)的零信任時,我們以人為本,對員工進行身分管理和多因子認證。同時,我們建立了一套管理公司設備的流程,每個公司設備都配備TPM模組和作業系統完整性驗證。這兩項工作確保了正確的人用正確的設備提供可信任的認證資訊。最後,我們再利用這些認證資訊對員工存取開發環境進行持續存取控制。
在用BeyondProd實現生產環境(Prod Environment)的零信任時,我們同樣試圖以人和流程作為信任的根本。 BeyondProd面對的問題是,生產環境並不存在與人的直接交互,於是我們建立了一套把生產環境中的軟體溯源到這些軟體的開發者(Software Provenance),從對開發者的認證和開發流程的加固開始,確保沒有任何單人能夠改變生產環境中的軟體的行為(No Unilateral Change)。
安全規則等級
羅馬不是一天造成的,推廣零信任同樣是漸進的過程。為了量化和激勵安全改進,我們用安全規則等級來衡量一個安全規則是否比另一個安全規則「更安全」。例如,在Binary Authorization for Borg體系中,我們引進了以下安全等級:
安全等級〇:無保護。此為最低的安全等級,代表該服務完全不被BAB保護。這種情況有可能是因為該系統沒有任何敏感權限,也有可能因為該系統使用了其他的與BAB等價的保護。
安全等級一:可審計的代碼。此等級的安全規則能夠確保對應服務所使用的軟體是在一個安全可驗證的環境中由已知的原始碼建構而成。
安全等級二:可信任的代碼。此等級的安全規則在能確保安全等級一之外,還能確保相應服務所用的軟體是由特定程式碼庫(例如Gmail自己的程式碼庫)中的經過程式碼評估(Code Review)和測試的程式碼建置而來。截至2020年2月,該等級為所有Google服務預設的保護等級。
安全等級三:可信任的代碼和配置。此等級的安全規則在能確保安全等級二之外,還能確保對應服務所使用的設定檔也像程式碼一樣經過了同樣的安全流程(Configuration as Code)。截至2020年2月,此等級為所有Google重點保護服務的預設等級。
警報制和授權制
在推廣零信任的過程中,為了給各方提供一個平緩的遷移體驗,我們並沒有直接禁止所有不符合安全規則訪問,而是在安全規則本身中提供警報制和授權制兩個模式。在警報制下,違反安全規則的存取並不會被阻止,而是會被記錄並報警給相關人員,而在授權制下,違反安全規則的存取會被立即阻止。這種雙體制的存在既給人機會根據報警不斷迭代和改進不合規的行為,又在不合歸的行為被杜絕後提供有效的機制收緊安全規則並防止回歸(Regression)。
要安全也要穩定
零信任的複雜度決定了其在維持系統穩定性(Reliability)上也會面臨新的挑戰。在實踐零信任的過程中,我們為大多數場景提供了緊急破壁機制(Break-glass Mechanism)。這保證了在緊急情況下,操作員能夠打破零信任系統的限制進行一些複雜的緊急操作。為了持續保障安全,一旦緊急破壁機制被調用,安全團隊會立刻收到警報,在破壁機制下的所有操作也會被詳細記錄在安全日誌中。這些安全日誌會被仔細審查以驗證破壁的必要性。這些安全日誌也會幫助設計新的零信任特性以避免在類似情況下再次呼叫緊急破壁機制。
關注內生風險
從防禦的角度來講,內生風險是外生風險的超集:當攻擊者攻陷任何一個內部人員(合法用戶或員工)的設備後,攻擊者便成了內部人員,所以無論是外部攻擊者還是內部違規人員,最終都會規約為內生風險。零信任從這個角度看就是假設任何一台主機都有可能被攻陷。
安全基礎建設
零信任的實施仰賴紮實的基礎安全架構,沒有基礎就沒有上層建築。谷歌零信任依賴以下基礎設施提供的基本安全保障:
- 資料加密和金鑰管理(Encryption and Key Management)
- 身分和存取管理(Identity and Access Management)
- 數位化人力資源管理(Digital Human Resource)
- 數位化設備管理(Digital Device Management)
- 資料中心安全(Data Center Security)
- 網路安全(Network Security)
- 主機安全(Host Security)
- 容器隔離(Container Isolation,gVisor)
- 可信任啟動(Trusted Boot)
- 可驗證建置(Verifiable Build)
- 軟體完整性驗證(Software Integrity Verification)
- 雙向TLS(mTLS)
- 基於服務的存取原則(Service Access Policy)
- 終端使用者令牌(End User Context Tokens)
- 配置即程式碼(Configuration as Code)
- 標準化開發與部署(Standard Development and Deployment)
其他
除以上經驗教訓外,從小規模開始迭代(Start small, then iterate),多層安全(Defense in depth),量化安全投資回報(Quantify return over investiment),透過標準化降低成本(Lowering cost through homogeneity),安全左移(Shifting left)等等,也是我們在實踐中累積下來的準則,在此不再贅述。
結論
做好零信任,20%靠理論,80%靠實踐。零信任的實踐方案並不唯一,筆者希望透過分享以上的一例零信任實踐,達到拋磚引玉的目的。歡迎大家批評指正!
本文來自投稿,不代表首席安全官立場,如若轉載,請註明出處:https://cncso.com/tw/googles-zero-trust-architecture.html